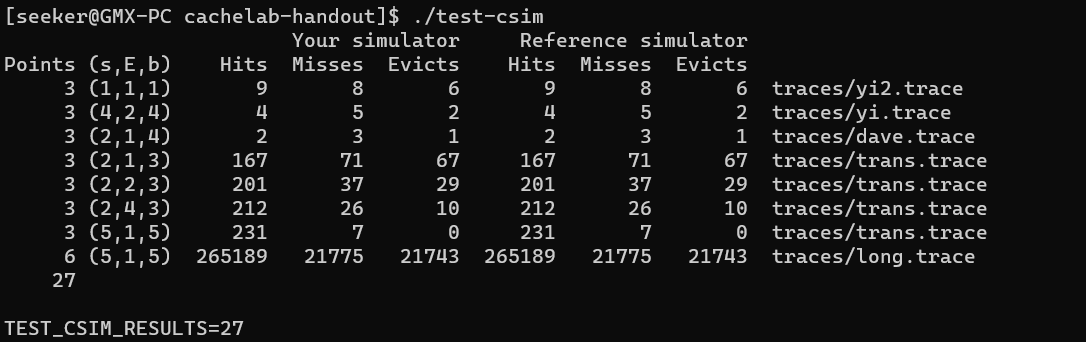
注意:如果使用WSL访问Windows文件的话,会遇到严重的磁盘IO问题,可能根本跑不出结果(就像DataLab的最后一问一样),所以最好把文件放到WSL的文件系统里,或者干脆物理机安装Linux然后在Linux下做😂
Part A: Writing a Cache Simulator 写这道题前最好先看看WriteUp 和习题课的ppt
这道题其实不难,但由于我太久没写c语言了,调试了半天Segmentation fault错误…
在内存中,cache被分成了S(S=2^s)个组(Set),一个Set有E行(Associaty),就像一个二维数组.
在查找cache时,先根据set_index找到对应的Set,然后遍历Set中的每一行,如果tag相同,则命中,否则miss
如果miss,则需要把数据从内存中读取到cache中,如果Set中的每一行都被占用了,则需要把最早的数据替换掉,这就是eviction
其中,这道题使用的缓存替换算法是LRU(Least Recently Used),即最近最少使用,也就是说,每次替换掉最早使用的数据
所以,在每一个缓存行都需要记录一个time,每次访问时,更新time,然后替换掉time最小的数据
注意,这道题并不是要我们实现一个缓存,只是模拟缓存的行为,统计hit,miss,eviction的次数,所以不需要存入数据
我的代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 #include "cachelab.h" #include <unistd.h> #include <getopt.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int h = 0 , v = 0 , s = 0 , E = 0 , b = 0 , S = 0 ;int hit,char file[1000 ];int time = 0 ; typedef struct { int valid;int tag;int time;void printUsage () ; void getconfig () ; void initCache () ; void readfile () ; int visitcache (unsigned int ) ; int main (int argc, char **argv) return 0 ;void printUsage () printf ("Usage: ./csim-ref [-hv] -s <num> -E <num> -b <num> -t <file>\n\ Options:\n\ -h Print this help message.\n\ -v Optional verbose flag.\n\ -s <num> Number of set index bits.\n\ -E <num> Number of lines per set.\n\ -b <num> Number of block offset bits.\n\ -t <file> Trace file.\n\n\ Examples:\n\ linux> ./csim-ref -s 4 -E 1 -b 4 -t traces/yi.trace\n\ linux> ./csim-ref -v -s 8 -E 2 -b 4 -t traces/yi.trace\n" );void getconfig (int argc, char **argv) int opt;while (-1 != (opt = getopt(argc, argv, "hvs:E:b:t:" )))switch (opt)case 'h' :exit (EXIT_FAILURE);break ;case 'v' :1 ;break ;case 's' :1 << s;break ;case 'E' :case 'e' :break ;case 'b' :break ;case 't' :strcpy (file, optarg);break ;default :printf ("Wrong Argument!\n" );exit (EXIT_FAILURE);break ;if (S <= 0 || s <= 0 || E <= 0 || b <= 0 || file == NULL )printf ("ERROR!" );exit (EXIT_FAILURE);void initCache () malloc (sizeof (cache_set) * S);if (Cac == NULL )printf ("Mem_ERROR!" );exit (EXIT_FAILURE);for (int i = 0 ; i < S; i++)malloc (sizeof (cache_line) * E);if (Cac[i] == NULL )printf ("Mem_ERROR!" );exit (EXIT_FAILURE);for (int j = 0 ; j < E; j++)0 ;0 ;0 ;void readfile () "r" );if (fp == NULL )printf ("FILE_ERROR!" );exit (EXIT_FAILURE);char identifier;unsigned address;int size;while (fscanf (fp, " %c %x,%d\n" , &identifier, &address, &size) > 0 )if (v == 1 )printf ("%c %x,%d " , identifier, address, size);switch (identifier)case 'I' :break ;case 'M' :break ;case 'L' :break ;case 'S' :break ;int visitcache (unsigned int address) int tag = address >> (s + b);int set_index = (address >> b) & (((unsigned )-1 ) >> (8 * sizeof (unsigned ) - s));int pos = 0 ;for (pos = 0 ; pos < E; pos++)if (Cac[set_index][pos].tag == tag && Cac[set_index][pos].valid == 1 )if (v == 1 )printf ("hit" );return 0 ;for (pos = 0 ; pos < E; pos++)if (Cac[set_index][pos].valid == 0 )1 ;if (v == 1 )printf ("miss" );return 1 ;0 ;for (int i = 0 ; i < E; i++)if (Cac[set_index][i].time < Cac[set_index][pos].time)if (v == 1 )printf ("miss eviction" );return 2 ;
Part B: Optimizing Matrix Transpose
如果使用WSL访问Windows文件的话,会遇到严重的磁盘IO问题,所以最好把文件放到WSL的文件系统里
32x32 这道题的目的是优化矩阵转置的性能,使用了分块的方法,每次转置一个8*8的小矩阵,这样可以利用缓存的局部性,减少缓存的miss
1 2 3 4 5 6 7 8 9 10 11 12 if (M == 32 )int i, j, m, n;for (i = 0 ; i < N; i += 8 )for (j = 0 ; j < M; j += 8 )for (m = i; m < i + 8 ; ++m)for (n = j; n < j + 8 ; ++n)
编译运行,发现miss依旧有344,达不到要求,还有什么可以优化的呢?
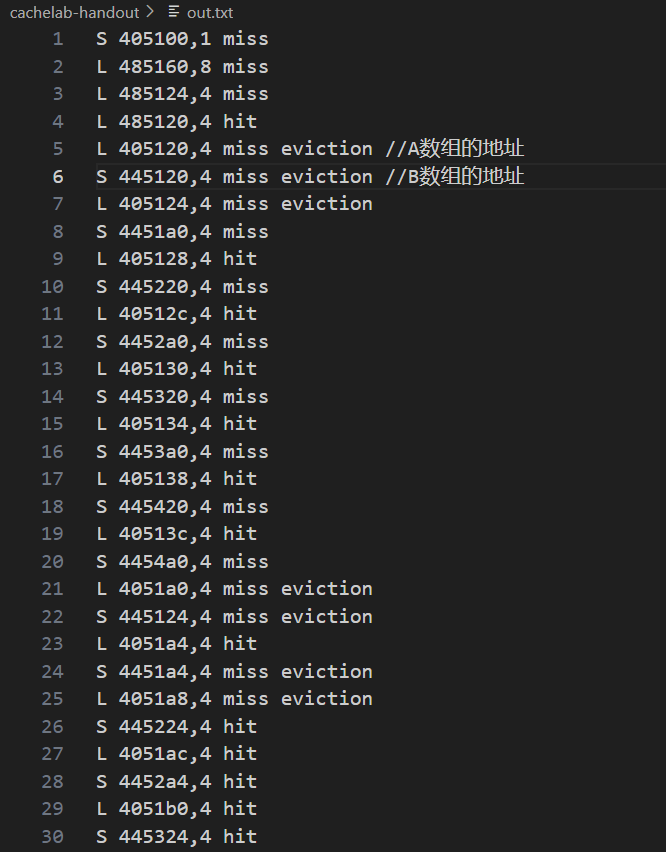
我看见WriteUP里面说到了会把各个函数内存访问情况写进trace.fi2文件中,用csim-ref把内存访问情况输出到out.txt里./csim-ref -v -s 5 -E 1 -b 5 -t trace.f1 >out.txt
通过观察,我们可以找到A,B数组的地址(在我的机器上分别是405120和445120),当它在对角线上时,似乎是被映射到同一个Cache Set中的,才导致了大量的 miss eviction.
改进如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 char transpose_submit_desc[] = "Transpose submission" ;void transpose_submit (int M, int N, int A[N][M], int B[M][N]) if (M == 32 )int i, j, m, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7, tmp8;for (i = 0 ; i < N; i += 8 )for (j = 0 ; j < M; j += 8 )for (m = 0 ; m < 8 ; ++m)1 ][j + m];2 ][j + m];3 ][j + m];4 ][j + m];5 ][j + m];6 ][j + m];7 ][j + m];1 ] = tmp2;2 ] = tmp3;3 ] = tmp4;4 ] = tmp5;5 ] = tmp6;6 ] = tmp7;7 ] = tmp8;
64x64 如果直接套用32x32矩阵的代码,结果是hits:3585, misses:4612, evictions:4580,远远超出了要求,有点离谱的是,miss数量是32x32矩阵的整整16倍!🤔
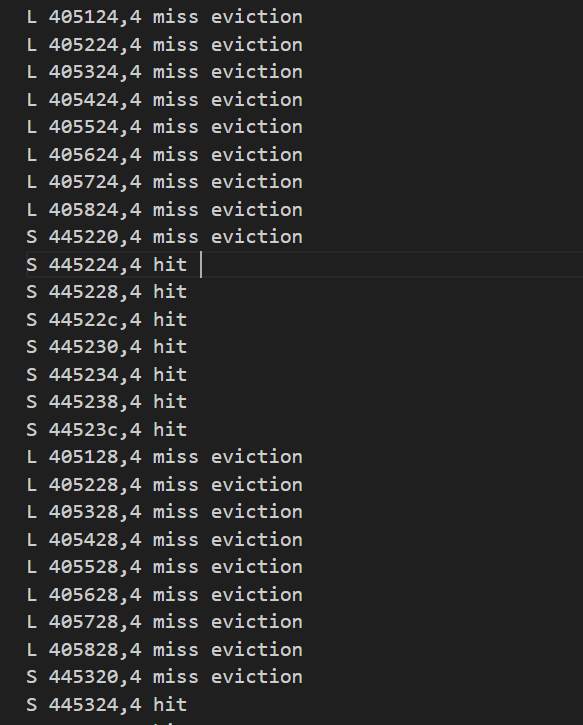
仔细一想,现在是64x64的矩阵,这样的话cache就只能存下矩阵的四行了,所以如果采用8x8的分块,会导致每一个块的前四行与后四行被映射到同一个cache中,在写入的时候产生miss
仔细观察,发现确实是这样,每8个load指令接着的store指令都是产生miss;
那就试试4x4分块咯;结果是hits:6545, misses:1652, evictions:1620,misses下降到了1652,离目标1300还有一点小差距
未完待续…,剩下的就有时间再写了
参考了知乎大佬的文章